
Understanding IPFS in Depth(4/6): What is MultiFormats?
In this part, we will talk about Why we need Multiformats, How it works and What you as a user/developer can do with it?

This post is a continuation(part 4) in a new “Understanding IPFS in Depth” series which will help anybody to understand the underlying concepts of IPFS. If you want an overview of what is IPFS and how it works, then you should check out the first part too 😊
 vasa
vasa
In part 3, we discussed the Significance of IPNS(InterPlanetary Naming System), How it Works, and its technical specification. We also went through a tutorial in which we created and hosted a website totally using IPFS Stack. You can check it out here:
vasa
In this part, we are going to dive deep into Multiformats. We will explore:
- Why do we Need Multiformats?
- Ok, I think we need it. But What is it?
- This seems great. Tell me how to use it.
I hope you learn a lot about IPFS from this series. Let’s get started!
Every choice in computing has a tradeoff.
This includes formats, algorithms, encodings, and so on. And even with a great deal of planning, decisions may lead to breaking changes down the road, or to solutions that are no longer optimal. Allowing systems to evolve and grow, without introducing breaking changes is important.
But, Why do we Need Multiformats?
To understand the need for Multiformats, let’s take an example of git protocol. A lot of people use it every single day to use services like Github, Gitlab, Bitbucket, etc. We know that git uses hashes for a lot of things. Right now git uses SHA-1 as its hashing algorithm.
These hashing algorithms play a very important role. They keep things secure. Not just in git, but in healthcare, global financial systems, and governments too.
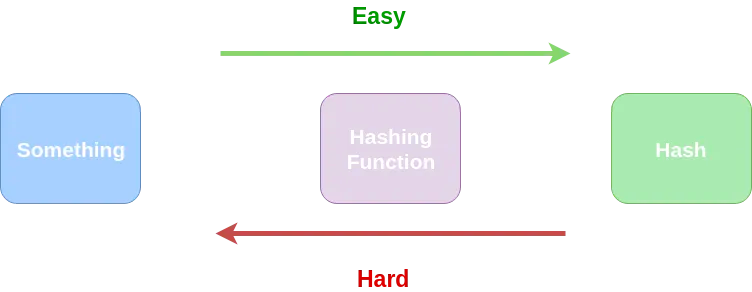
The way they work is that they are one-way functions. So, you can get an output(Hash) from an input(something) using the hashing function, but it’s practically impossible to get the input from the output.
But with time, as more powerful computers are being developed, some of these hash functions have started failing; meaning now you can get the input from the output, hence breaking the security of the systems that use the function. This is what happened to the MD5 hash function.
So, just like MD5, someday SHA1 will be broken…and then we would need to use a better hashing function. But the problem here is that, as these algorithms are hard-wired to the ecosystem, it’s really hard to make such changes. Plus what happens to all the codebase that was using the old SHA1? All of that will be rendered incompatible…that sucks!
And this problem of non-future-proofing and incompatibility is not just limited to the hashing algorithms. The network protocols are also a prime host of these problems.
Take the example of HTTP/2, which was introduced in 2015. From a network’s viewpoint, HTTP/2 made a few notable changes. As it’s a binary protocol, any device that assumes it’s HTTP/1.1 is going to break. And that meant changing all the things that use HTTP/1.1, which includes browsers and your web servers.
So, summing up there are a number of problems that we face:
- Introducing breaking changes to update systems with better security.
- Introducing breaking changes due to some unforeseen issues.
- And sometimes we need to make trade-offs when it comes to multiple numbers of options, each having a desired trait, but you can have only one. Ever been to a candy store, where you wanted to buy the whole store…but your Mom let you buy only one…Yeah, it’s the same with tech too.
These problems not only break things but also make the whole development cycle slow, as it takes a lot of time to carefully shift the whole system.
Almost every system that we see today was NEVER designed keeping the fact in mind that someday it is going to be outdated.
This is not the way we want our future to be. So, we need to embrace the fact that things change.
The Multiformats Project introduces a set of standards/protocols that embrace this fact and allows multiple protocols to co-exist so that even if there is a breaking change, the ecosystem still supports all the versions of the protocol.
Now, as we know we know “Why”, let’s see “What”…
What are Multiformats?
The Multiformats Project is a collection of protocols that aim to future-proof systems, today. They do this mainly by enhancing format values with self-description. This allows interoperability, protocol agility, and helps us avoid lock-in.
The self-describing aspects of the protocols have a few stipulations:
- They MUST be in-band (with the value); not out-of-band (in context).
- They MUST avoid lock-in and promote extensibility.
- They MUST be compact and have a binary-packed representation.
- They MUST have a human-readable representation.
Multiformat protocols
Currently, we have the following multiformat protocols:
- Multihash: Self-describing hashes
- Multiaddr: Self-describing network addresses
- Multibase: Self-describing base encodings
- Multicodec: Self-describing serialization
- Multistream: Self-describing stream network protocols
- Multistream-select: Friendly protocol multiplexing.
- Multigram(WIP): Self-describing packet network protocols
- Multikey: cryptographic keys and artifacts
Each of the projects has its list of implementations in various languages.
Ok. This all sounds a bit complex. Let’s Break it down a bit
We will go through each of these multiformat protocols and try to understand how they work.
Multihash
Multihash is a protocol for differentiating outputs from various well-established hash functions, addressing size + encoding considerations. It is useful to write applications that future-proof their use of hashes and allow multiple hash functions to coexist.
Safer, easier cryptographic hash function upgrades
Multihash is particularly important in systems that depend on cryptographically secure hash functions. Attacks may break the cryptographic properties of secure hash functions. These cryptographic breaks are particularly painful in large tool ecosystems, where tools may have made assumptions about hash values, such as function and digest size. Upgrading becomes a nightmare like all tools which make those assumptions would have to be upgraded to use the new hash function and new hash digest length. Tools may face serious interoperability problems or error-prone special casing. As we discussed earlier, there can be a number of problems in the git example:
- How many programs out there assume a git hash is a sha1 hash?
- How many scripts assume the hash value digest is exactly 160 bits?
- How many tools will break when these values change?
- How many programs will fail silently when these values change?
This is precisely where Multihash shines. It was designed for upgrading.
When using Multihash, a system warns the consumers of its hash values that these may have to be upgraded in case of a break. Even though the system may still only use a single hash function at a time, the use of multihash makes it clear to applications that hash values may use different hash functions or be longer in the future. Tooling, applications, and scripts can avoid making assumptions about the length, and read it from the multihash value instead. This way, the vast majority of tooling — which may not do any checking of hashes — would not have to be upgraded at all. This vastly simplifies the upgrade process, avoiding the waste of hundreds or thousands of software engineering hours, deep frustrations, and high blood pressure.
The MultiHash Format
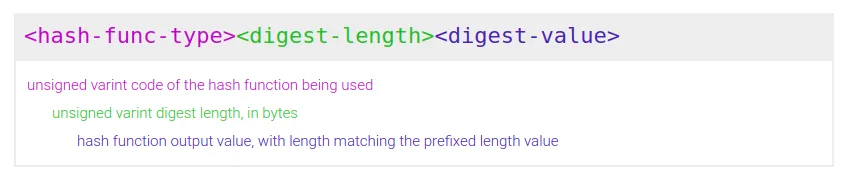
A multihash follows the TLV (type-length-value) pattern.
- the type
<hash-func-type>is an unsigned variable integer identifying the hash function. There is a default table, and it is configurable. The default table is the multicodec table. - the length
<digest-length>is an unsigned variable integer counting the length of the digest, in bytes - the value
<digest-value>is the hash function digest, with a length of exactly<digest-length>bytes.
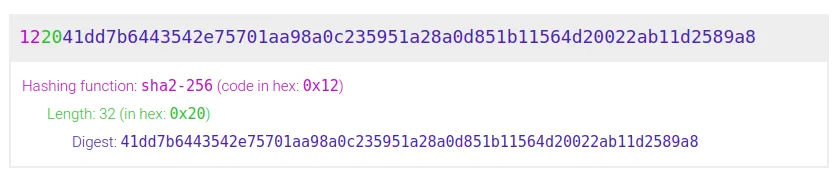
To understand the significance of multihash format, let’s use some visual aid.
Consider these 4 different hashes of the same input

Same length: 256 bits
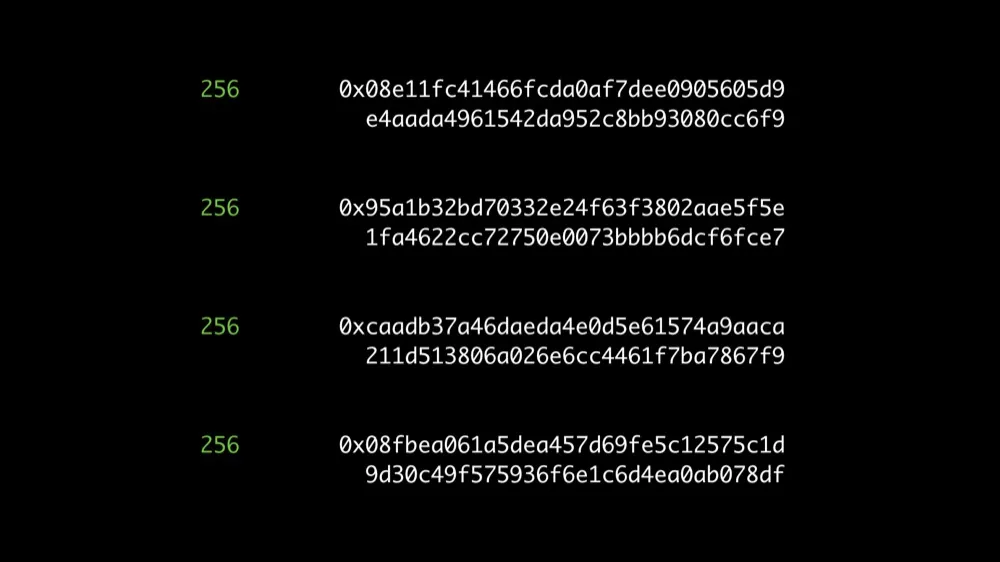
Different hash functions
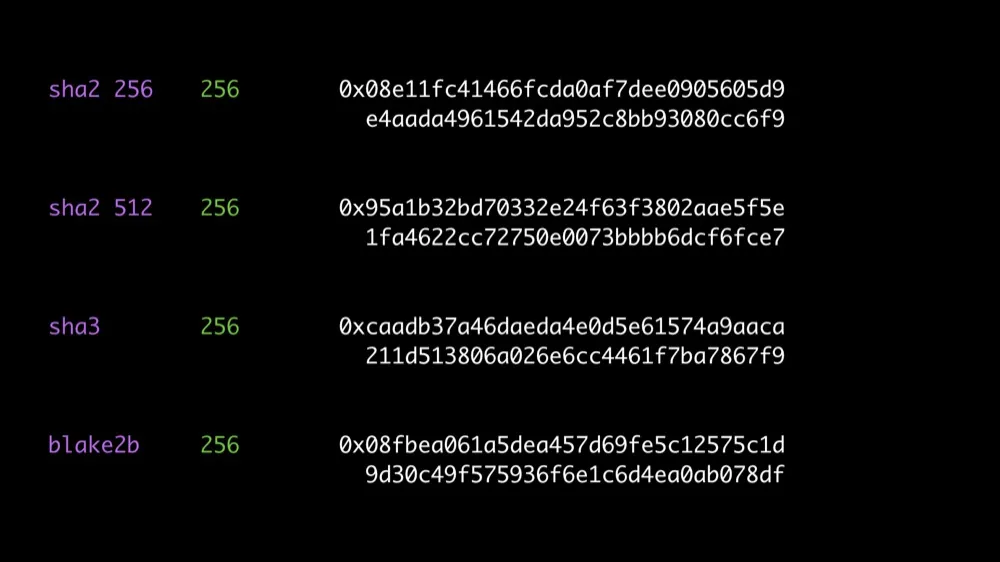
Idea: self-describe the values to distinguish
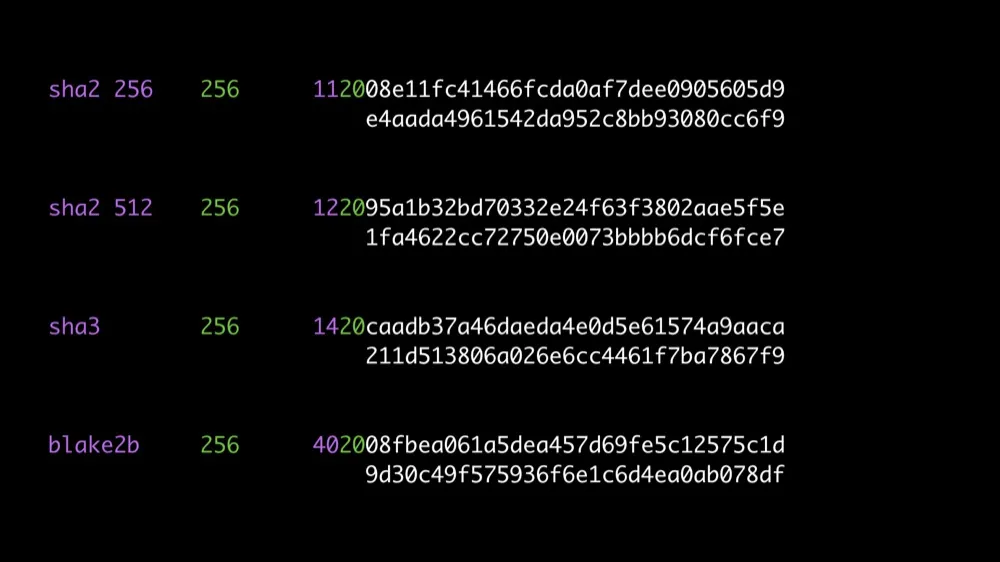
Multihash: fn code + length prefix

Multihash: a pretty good multiformat

I hope this sums up Multihash pretty well.
Implementations
You can find a number of multihash implementations in multiple languages.
Tutorial
You can find a hands-on tutorial on multihash at the end of this post.
Multiaddr
Multiaddr is a format for encoding addresses from various well-established network protocols. It is useful to write applications that future-proof their use of addresses and allow multiple transport protocols and addresses to coexist.
Network Protocol Ossification
The current network addressing scheme in the internet IS NOT self-describing. Addresses of the following forms leave much to interpretation and side-band context. The assumptions they make cause applications to also make those assumptions, which causes lots of “this type of address”-specific code. The network addresses and their protocols rust into place, and cannot be displaced by future protocols because the addressing prevents change.
For example, consider:
127.0.0.1:9090 # ip4. is this TCP? or UDP? or something else?
[::1]:3217 # ip6. is this TCP? or UDP? or something else?
http://127.0.0.1/baz.jpg
http://foo.com/bar/baz.jpg
//foo.com:1234
# use DNS, to resolve to either ip4 or ip6, but definitely use
# tcp after. or maybe quic... >.<
# these default to TCP port :80.Instead, when addresses are fully qualified, we can build applications that will work with network protocols of the future, and do not accidentally ossify the stack.
/ip4/127.0.0.1/udp/9090/quic
/ip6/::1/tcp/3217
/ip4/127.0.0.1/tcp/80/http/baz.jpg
/dns4/foo.com/tcp/80/http/bar/baz.jpg
/dns6/foo.com/tcp/443/httpsMultiaddr Format
A multiaddr value is a recursive (TLV)+ (type-length-value repeating) encoding. It has two forms:
- a human-readable version to be used when printing to the user (UTF-8)
- a binary-packed version to be used in storage, transmissions on the wire, and as a primitive in other formats.
The human-readable version
- path notation nests protocols and addresses, for example:
/ip4/127.0.0.1/udp/4023/quic(this is the repeating part). - a protocol MAY be only a code, or also have an address value (nested under a
/) (eg./quicand/ip4/127.0.0.1) - the type
<addr-protocol-str-code>is a string code identifying the network protocol. The table of protocols is configurable. The default table is the multicodec table. - the value
<addr-value>is the network address value, in natural string form.
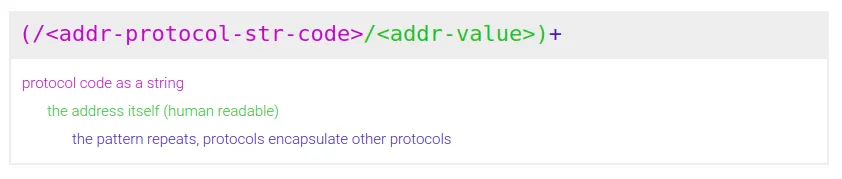
The binary-packed version
- the type
<addr-protocol-code>is a variable integer identifying the network protocol. The table of protocols is configurable. The default table is the multicodec table. - the length is an unsigned variable integer counting the length of the address value, in bytes.
- The length is omitted by protocols who have an exact address value size, or no address value.
- the value
<addr-value>is the network address value, of lengthL. - The value is omitted by protocols who have no address value.
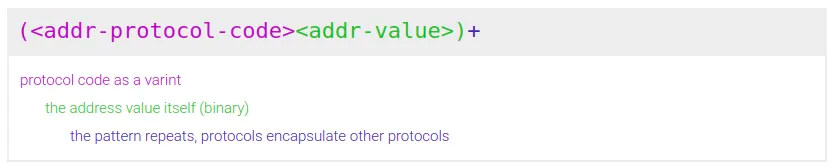
Implementations
You can find a number of multiaddr implementations in multiple languages.
Tutorial
You can find a hands-on tutorial on multiaddr at the end of this post.
Multibase
Multibase is a protocol for disambiguating the encoding of base-encoded (e.g., base32, base64, base58, etc.) binary appearing in the text.
When text is encoded as bytes, we can usually use a one-size-fits-all encoding (UTF-8) because we’re always encoding to the same set of 256 bytes (+/- the NUL byte). When that doesn’t work, usually for historical or performance reasons, we can usually infer the encoding from the context.
However, when bytes are encoded as text (using a base encoding), the base choice of base encoding is often restricted by the context. Worse, these restrictions can change based on where the data appears in the text. In some cases, we can only use [a-z0-9]. In others, we can use a larger set of characters but need a compact encoding. This has lead to a large set of “base encodings”, one for every use-case. Unlike when encoding text to bytes, we can't just standardize around a single base encoding because there is no optimal encoding for all cases.
Unfortunately, it’s not always clear what base encoding is used; that’s where multibase comes in. It answers the question:
Given data d encoded into text s, what base is it encoded with?
Multibase Format
The Format is:
<base-encoding-character><base-encoded-data>Where <base-encoding-character> is used according to the multibase table.
Here is an example to show how it works.
Consider the following encodings of the same binary string:
4D756C74696261736520697320617765736F6D6521205C6F2F # base16 (hex)
JV2WY5DJMJQXGZJANFZSAYLXMVZW63LFEEQFY3ZP # base32
YAjKoNbau5KiqmHPmSxYCvn66dA1vLmwbt # base58
TXVsdGliYXNlIGlzIGF3ZXNvbWUhIFxvLw== # base64And consider the same encodings with their multibase prefix
F4D756C74696261736520697320617765736F6D6521205C6F2F # base16 F
BJV2WY5DJMJQXGZJANFZSAYLXMVZW63LFEEQFY3ZP # base32 B
zYAjKoNbau5KiqmHPmSxYCvn66dA1vLmwbt # base58 z
MTXVsdGliYXNlIGlzIGF3ZXNvbWUhIFxvLw== # base64 The base prefixes used are: F, B, z, M.
Now, you can write self-descriptive encoded text :)
Implementations
You can find a number of multibase implementations in multiple languages.
Now, the next two, Multicodec and Multistream are a bit inter-related, so I will try to explain the motivation behind these two, but you may need to read them both to understand each one of them.
Tutorial
You can find a hands-on tutorial on multibase at the end of this post.
Multicodec
Motivation
Multistreams are self-describing protocol/encoding streams. Multicodec uses an agreed-upon “protocol table”. It is designed for use in short strings, such as keys or identifiers (i.e CID).
How does the protocol work?
multicodec is a self-describing multiformat, it wraps other formats with a tiny bit of self-description. A multicodec identifier is a varint.
A chunk of data identified by multicodec will look like this:
<multicodec><encoded-data>
# To reduce the cognitive load, we sometimes might write the same line as:
<mc><data>Another useful scenario is when using the multicodec as part of the keys to access data, for example:
# suppose we have a value and a key to retrieve it
"<key>" -> <value>
# we can use multicodec with the key to know what codec the value is in
"<mc><key>" -> <value>It is worth noting that multicodec works very well in conjunction with multihash and multiaddr, as you can prefix those values with a multicodec to tell what they are.
MulticodecProtocol Tables
Multicodec uses “protocol tables” to agree upon the mapping from one multicodec code. These tables can be application specific, though — like with other multiformats — we will keep a globally agreed upon table with common protocols and formats.
Multicodec Path, also known as multistream
Multicodec defines a table for the most common data serialization formats that can be expanded overtime or per application bases, however, in order for two programs to talk with each other, they need to know beforehand which table or table extension is being used.
In order to enable self-descriptive data formats or streams that can be dynamically described, without the formal set of adding a binary packed code to a table, we have multistream, so that applications can adopt multiple data formats for their streams and with that create different protocols.
Now let’s answer a few questions to understand its significance.
Why Multicodec?
Because multistream is too long for identifiers. We needed something shorter.
Why varints?
So that we have no limitation on protocols.
Don’t we have to agree on a table of protocols?
Yes, but we already have to agree on what protocols themselves are, so this is not so hard. The table even leaves some room for custom protocol paths, or you can use your own tables. The standard table is only for common things.
Where did multibase go?
For a period of time, the multibase prefixes lived in this table. However, multibase prefixes are symbols that may map to multiple underlying byte representations (that may overlap with byte sequences used for other multicodecs). Including them in a table for binary/byte identifiers lead to more confusion than it solved.
You can still find the table in multibase.csv.
Implementations
You can find a number of multicodec implementations in multiple languages.
Tutorial
You can find a hands-on tutorial on multicodec at the end of this post.
Multistream
Motivation
Multicodecs are self-describing protocol/encoding streams. (Note that a file is a stream). It’s designed to address the perennial problem:
I have a bitstring, what codec is the data coded with?
Instead of arguing about which data serialization library is the best, let’s just pick the simplest one now, and build upgradability into the system. Choices are never forever. Eventually, all systems are changed. So, embrace this fact of reality, and build change into your system now.
Multicodec frees you from the tyranny of past mistakes. Instead of trying to figure it all out beforehand, or continue using something that we can all agree no longer fits, why not allow the system to evolve and grow with the use cases of today, not yesterday.
To decode an incoming stream of data, a program must either
- know the format of the data a priori, or
- learn the format from the data itself.
(1) precludes running protocols that may provide one of many kinds of formats without prior agreement on which. multistream makes (2) neat using self-description.
Moreover, this self-description allows straightforward layering of protocols without having to implement support in the parent (or encapsulating) one.
How does the protocol work?
multistream is a self-describing multiformat, it wraps other formats with a tiny bit of self-description:
<varint-len>/<codec>\n<encoded-data>For example, let’s encode a JSON doc:
// encode some json
const buf = new Buffer(JSON.stringify({ hello: 'world' }))
const prefixedBuf = multistream.addPrefix('json', buf) // prepends multicodec ('json')
console.log(prefixedBuf)
// <Buffer 06 2f 6a 73 6f 6e 2f 7b 22 68 65 6c 6c 6f 22 3a 22 77 6f 72 6c 64 22 7d>
console.log(prefixedBuf.toString('hex'))
// 062f6a736f6e2f7b2268656c6c6f223a22776f726c64227d
// let's get the Codec and then get the data back
const codec = multicodec.getCodec(prefixedBuf)
console.log(codec)
// json
console.log(multistream.rmPrefix(prefixedBuf).toString())
// "{ \"hello\": \"world\" }So, buf is:
hex: 062f6a736f6e2f7b2268656c6c6f223a22776f726c64227d
ascii: /json\n"{\"hello\":\"world\"}"Note that on the ASCII version, the varint at the beginning is not being represented, you should account that.
The Protocol Path
multistream allows us to specify different protocols in a universal namespace, that way being able to recognize, multiplex, and embed them easily. We use the notion of a path instead of an id because it is meant to be a Unix-friendly URI.
A good path name should be decipherable — meaning that if some machine or developer — who has no idea about your protocol — encounters the path string, they should be able to look it up and resolve how to use it.
An example of a good path name is:
/bittorrent.org/1.0An example of a great path name is:
/ipfs/Qmaa4Rw81a3a1VEx4LxB7HADUAXvZFhCoRdBzsMZyZmqHD/ipfs.protocol
/http/w3id.org/ipfs/1.1.0These path names happen to be resolvable — not just in a “multistream muxer(e.g multistream-select)” but on the internet as a whole (provided the program (or OS) knows how to use the /ipfs and /http protocols).
Now, let’s answer a few questions to understand its significance.
Why Multistream?
Today, people speak many languages and use common ones as an interface. But every “common language” has evolved over time, or even fundamentally switched. Why should we expect programs to be any different?
And the reality is they’re not. Programs use a variety of encodings. Today we like JSON. Yesterday, XML was all the rage. XDR solved everything, but it’s kinda retro. Protobuf is still too cool for school. capnp (“cap and proto”) is for cerealization hipsters.
The one problem is figuring out what we’re speaking. Humans are pretty smart, we pick up all sorts of languages over time. And we can always resort to pointing and grunting (the ASCII of humanity).
Programs have a harder time. You can’t keep piping JSON into a protobuf decoder and hope they align. So we have to help them out a bit. That’s what multicodec is for.
Full paths are too big for my use case, is there something smaller?
Yes, check out multicodec. It uses a varint and a table to achieve the same thing.
Implementations
You can find a number of multistream implementations in multiple languages.
Tutorial
You can find a hands-on tutorial on multisteam at the end of this post.
Multistream-Select
Motivation
Some protocols have sub-protocols or protocol-suites. Often, these sub-protocols are optional extensions. Selecting which protocol to use — or even knowing what is available to choose from — is not simple.
What if there was a protocol that allowed mounting or nesting other protocols, and made it easy to select which protocol to use. (This is sort of like ports, but managed at the protocol level — not the OS — and human-readable).
How does the Protocol work?
The actual protocol is very simple. It is a multistream protocol itself, it has a multicodec header. And it has a set of other protocols available to be used by the remote side. The remote side must enter:
> <multistream-header>
> <multistream-header-for-whatever-protocol-that-we-want-to-speak>for example:
> /ipfs/QmdRKVhvzyATs3L6dosSb6w8hKuqfZK2SyPVqcYJ5VLYa2/multistream-select/0.3.0
> /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3- The
<multistream-header-of-multistream>ensures a protocol selection is happening. - The
<multistream-header-for-whatever-protocol-is-then-selected>hopefully describes a valid protocol listed. Otherwise, we return ana("not available") error:
na\n
# in hex (note the varint prefix = 3)
# 0x036e610afor example:
# open connection + send multicodec headers, inc for a protocol not available
> /ipfs/QmdRKVhvzyATs3L6dosSb6w8hKuqfZK2SyPVqcYJ5VLYa2/multistream-select/0.3.0
> /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/some-protocol-that-is-not-available
# open connection + signal protocol not available.
< /ipfs/QmdRKVhvzyATs3L6dosSb6w8hKuqfZK2SyPVqcYJ5VLYa2/multistream-select/0.3.0
< na
# send a selection of a valid protocol + upgrade the conn and send traffic
> /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3
> <dht-traffic>
> ...
# receive a selection of the protocol + sent traffic
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3
< <dht-traffic>
< ...Note 1: Every multistream message is a “length-prefixed-message”, which means that every message is prepended by a varint that describes the size of the message.
Note 2: Every multistream message is appended by a \n character, this character is included in the byte count that is accounted for by the prepended varint.
Listing
It is also possible to “list” the available protocols. A list message is simply:
ls\n
# in hex (note the varint prefix = 3)
0x036c730aSo a remote side asking for a protocol listing would look like this:
# request
<multistream-header-for-multistream-select>
ls\n
# response
<varint-total-response-size-in-bytes><varint-number-of-protocols>
<multicodec-of-available-protocol>
<multicodec-of-available-protocol>
<multicodec-of-available-protocol>
...For example
# send request
> /ipfs/QmdRKVhvzyATs3L6dosSb6w8hKuqfZK2SyPVqcYJ5VLYa2/multistream-select/0.3.0
> ls
# get response
< /ipfs/QmdRKVhvzyATs3L6dosSb6w8hKuqfZK2SyPVqcYJ5VLYa2/multistream-select/0.3.0
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/1.0.0
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-bitswap/0.4.3
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-bitswap/1.0.0
# send selection, upgrade connection, and start protocol traffic
> /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3
> <ipfs-dht-request-0>
> <ipfs-dht-request-1>
> ...
# receive selection, and upgraded protocol traffic.
< /ipfs/QmVXZiejj3sXEmxuQxF2RjmFbEiE9w7T82xDn3uYNuhbFb/ipfs-dht/0.2.3
< <ipfs-dht-response-0>
< <ipfs-dht-response-1>
< ...Example
# greeting
> /http/multiproto.io/multistream-select/1.0
< /http/multiproto.io/multistream-select/1.0
# list available protocols
> /http/multiproto.io/multistream-select/1.0
> ls
< /http/google.com/spdy/3
< /http/w3c.org/http/1.1
< /http/w3c.org/http/2
< /http/bittorrent.org/1.2
< /http/git-scm.org/1.2
< /http/ipfs.io/exchange/bitswap/1
< /http/ipfs.io/routing/dht/2.0.2
< /http/ipfs.io/network/relay/0.5.2
# select protocol
> /http/multiproto.io/multistream-select/1.0
> ls
> /http/w3id.org/http/1.1
> GET / HTTP/1.1
>
< /http/w3id.org/http/1.1
< HTTP/1.1 200 OK
< Content-Type: text/html; charset=UTF-8
< Content-Length: 12
<
< Hello WorldImplementations
You can find a number of multistream-select implementations in multiple languages.
Tutorial
You can find a hands-on tutorial on multistream-select at the end of this post.
Multigram
Multigram operates on datagrams, which can be UDP packets, Ethernet frames, etc. and which are unreliable and unordered. All it does is prepend a field to the packet, which signifies the protocol of this packet. The endpoints of the connection can then use different packet handlers per protocol.
As Multigram is WIP, I will not go through it in depth. But you want to track its development, you can visit here.
Alright, now as we have covered “What”, let’s play with it a bit to get a taste of its power 🔥
Let’s Play with Multiformats 🔥🔥🔥
Here we will play a bit with Multihash, Multiaddr, and Multicodec. You can also find the complete code for this tutorial here.
We will use the JS implementations for our tutorial.
Project Setup
Create a folder named multiformats_tut . Now, go into the folder.
Installation
Make sure that you have installed npm and nodejs on your system.
Run this command.
npm install multiaddr multihashes multibaseLet’s write some code
Multihash
Create a file multihash_tut.js inside the folder.
var multihash = require('multihashes')
var buf = new Buffer.from('0beec7b5ea3f0fdbc95d0dd47f3c5bc275da8a33', 'hex')
console.log(buf)
// < Buffer 0b ee c7 b5 ea 3f 0f db c9 5d 0d d4 7f 3c 5b c2 75 da 8a 33 >
var encoded = multihash.encode(buf, 'sha1')
console.log(encoded)
// <Buffer 11 14 0b ee c7 b5 ea 3f 0f db c9 5d 0d d4 7f 3c 5b c2 75 da 8a 33 >
var decoded = multihash.decode(encoded)
console.log(decoded)
/**
{
code: 17,
name: 'sha1',
length: 20,
digest:
<Buffer 0b ee c7 b5 ea 3f 0f db c9 5d 0d d4 7f 3c 5b c2 75 da 8a 33>
}
*/Now, run the code using node multihash_tut.js .
You will see the same output that we added in the comments.
Multiaddr
Create a file multiaddr_tut.js inside the folder.
var Multiaddr = require('multiaddr')
var home = new Multiaddr('/ip4/127.0.0.1/tcp/80')
// <Multiaddr 047f000001060050 - /ip4/127.0.0.1/tcp/80>
console.log(home.buffer)
// <Buffer 04 7f 00 00 01 06 00 50>
console.log(home.toString())
// '/ip4/127.0.0.1/tcp/80'
console.dir(home.protos())
// [ { code: 4, size: 32, name: 'ip4', resolvable: false, path: false },
// { code: 6, size: 16, name: 'tcp', resolvable: false, path: false } ]
console.dir(home.nodeAddress())
// { family: 4, address: '127.0.0.1', port: '80' }
var proxy = new Multiaddr('/ip4/192.168.2.1/tcp/3128')
// <Multiaddr 04c0a80201060c38 - /ip4/192.168.2.1/tcp/3128>
var full = proxy.encapsulate(home)
// <Multiaddr 04c0a80201060c38047f000001060050 - /ip4/192.168.2.1/tcp/3128/ip4/127.0.0.1/tcp/80>
console.log(full.toString())
// '/ip4/192.168.2.1/tcp/3128/ip4/127.0.0.1/tcp/80'Now run the code using node multiaddr_tut.js .
You will see the same output that we added in the comments.
Multibase
Create a file multibase_tut.js inside the folder.
const multibase = require('multibase')
//Encodes a buffer into one of the supported encodings, prefixing it with the multibase code
const encodedBuf = multibase.encode('base58btc', new Buffer.from('hey, how is it going'))
console.log(encodedBuf)
// <Buffer 7a 32 54 4d 66 44 65 6e 62 67 7a 7a 38 53 39 37 62 68 62 38 78 51 52 58 53 70 32 63 6e>
//Checks if buffer or string is encoded
const value = multibase.isEncoded(encodedBuf)
console.log(value)
// base58btc
//Decodes a buffer or string
const decodedBuf = multibase.decode(encodedBuf)
console.log(decodedBuf.toString())
// hey, how is it goingNow run the code using node multibase_tut.js .
You will see the same output that we added in the comments.
Multicodec
You can find multicodec tutorial here.
Multistream
You can find multistream tutorial here.
Multistream-select
You can find multistream-select tutorial here.
Congratulations🎉🎉 You now have the power to Future-proof a lot of things.
That’s it for this part. In the next part, we will explore Libp2p. You can check it out here:
vasa